kafka数据实时同步引发的边界问题
数据库从kafka集群中实时增量同步数据, 由于kafka的默认保留7天日志的问题, 引发的边界情况下, 可能丢数据的思考
场景描述
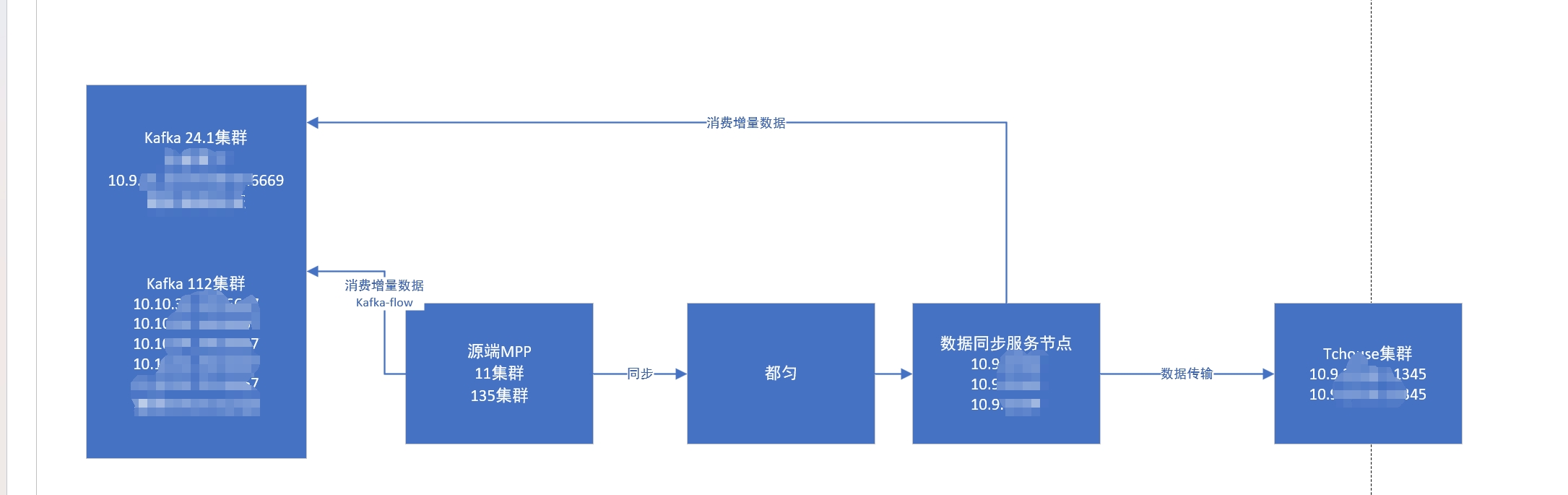
如下图所示, 这是1条数据同步的链路, 其中数据同步服务通过2种方式将数据同步到最终的Tchouse集群中, 用以实现和生产环境的数据保持一致
- 存量同步: 使用copy命令从都匀环境中将数据表copy下来, 然后直接insert到Tchouse集群中
- 增量同步: 从t-7开始读取kafka中的数据DML情况, 然后在Tchouse集群中回放, 从而实现数据的增量同步
场景的异常情况
由于存量同步采用的是copy insert的方式, 因此整个任务是一次性的, 但是增量同步的过程中, 由于是不断消费kafka中的数据, 因此如果业务侧修改了源表的DDL, 但是目标端Tchouse集群中没有修改, 就会导致报错, 从而增量同步停止, 就必须得人工介入, 解决完任务后, 继续从停止消费的offset开始消费, 而kafka的数据是保留7天, 超过7天就会出现数据丢失的情况
阶段1-正常
正常情况下, Tchouse集群中有1-9天的数据, 而增量任务此时正在同步第10天的数据, 而kafka集群中有6-12点的数据

阶段2-异常
当生产环境的表结构变化, 而没有同步到目标端Tchouse集群时, 就会导致增量任务报错, 从而停止, 此时Tchouse集群中有1-9天的数据, 而增量任务在同步第10天的数据时候, 任务停止了, 需要人工接入进行处理

阶段3-边界问题-经过6天的处理
经过人工介入后, 故障处理完成, 可以重新开启增量任务, 此时Tchouse集群中的数据为1-9天, 而kafka集群因为只能存储7天的数据, 因此此时只有12-18号的数据信息, 而10-11号的数信息被删除了, 开启增量任务后, 增量任务会从之前停止的时候, 开始继续消费, 也就是第10天, 但是第10天的offset在kafka集群中不存在, 因此kafka集群会根据auto-offset-reset参数调整客户端的offset

阶段4-kafka的offset调整
kafka的auto-offset-reset有3个值
- none: 客户端提交不存在的offset, 则会抛出异常
- earliest: 客户端提交不存在的offset, 则会将客户端指向最早的offset, 即图中的12
- latest: 默认值, 客户端提交不存在的offset, 则会将客户端执行最新的offset, 即图中的18

思考
- 不论kafka的auto-offset-reset是earliest还是latest, 都会导致边界情况下, Tchouse集群中丢失一部分数据, 区别就是丢失的多与少而已
- 增量任务向Tchouse集群中提交的数据其实是sql语句, 如果后续提交的sql没有对丢失的数据引用, 那么增量任务就不会报错, 那就会导致数据错误, 这比数据库故障还可怕
解决方法
- 修改kafka集群的auto-offset-reset为none, 这样, 最起码在丢失数据的时候, 会抛出异常, 可以让人知道, 从而进行新的存量同步和增量同步, 该方案可行性最高
- 调整kafka集群的日志默认保留时间到更长, 需要业务侧配合, 可行性较差
kafka数据实时同步引发的边界问题